Data Loading Pipeline
torch.utlis.data Package
PyTorch’s data package plays a crucial role in deep learning pipelines, with three foundational classes at its core: Dataset, IterableDataset, and DataLoader. The Dataset class supports both map-style and iterable-style datasets, while the DataLoader efficiently handles the complex tasks of data loading, sampling, batching, and data feeding. For map-style datasets, custom Samplers can be used to meet specific needs. IterableDataset is particularly valuable for dealing with data that exceeds available memory or requires computationally expensive loading. This class allows data to be processed and streamed in an iterative manner.Furthermore, PyTorch’s DataLoader is adept at handling asynchronous and multiprocessing workflows, enhancing data loading performance through configurable parameters such as num_workers, pin_memory, and multiprocessing, all tailored to specific hardware and data loading requirements.
Map-style Dataset Pipeline
Map-style Dataset Pipeline
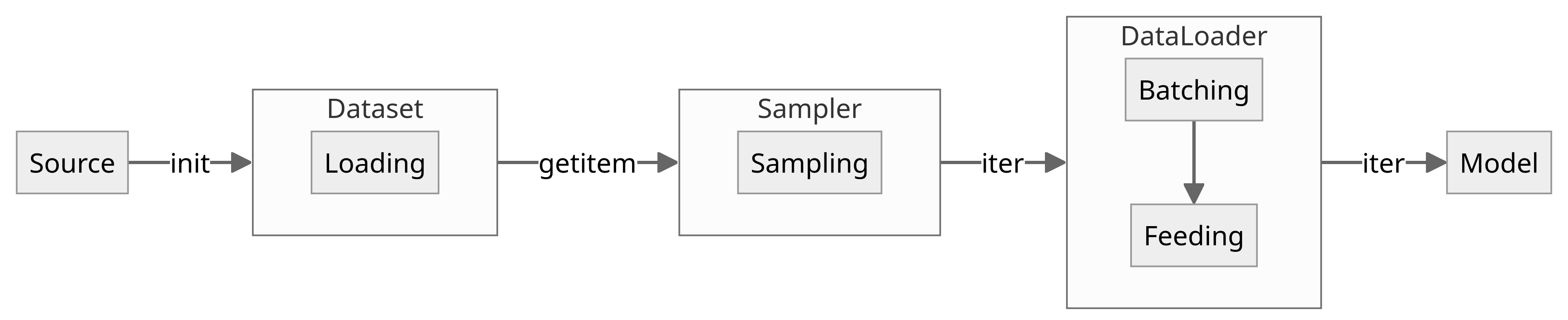
Dataset: Map-Style Dataset Subclass
__init__(): Required
Load the entire data into the dataset when it is constructed.
The entire dataset must be able to be loaded into memory and processed by the CPU without exceeding the limits.
It is not suitable for streaming data.
__getitem__(): Required
Map-style fetching method using integer or string keys.
If using string keys, a custom Sampler must be supplied.
__len__(): Optional
To sample the data, the Sampler needs this method to get the size of the dataset.
A custom Sampler that iterates over the dataset without using this method can only be used to fetch the data one by one and wait for the next one if it is not loading already. This can be useful for certain applications, such as streaming data. However, it is not generally recommended for sampling, as it is inefficient and does not allow you to use PyTorch’s built-in sampling features.
Using the IterableDataset class is the best way to deal with streaming data
This method is optional for Dataset subclasses, but it is required for most Map-Style Datasets.
__getitems__(): Optional
This method is optional. It can speed up data loading for sampling and batching.
A batch of samples can be fetched using a list of integer or string keys.
DataLoader
__init__(): Constructor
Setup dataset, sampler, batching size and more.
If there is no custom Sampler or built-in Sampler setup, the built-in sampler will be used over the dataset in a sequential order, without shuffling.
Batch_size, shuffle and drop_last for built-in sampler.
Batch_size and drop_last for custom sampler.
Batch_sampler controls itself.
__iter__(): Iterator
Iterate over the Sampler to load the data in batches.
This is the feeding method for models.
Sampler: Optional Subclass
__init__(): Optional
Setup dataset and get the size of the dataset.
__iter__(): Required
Custom sampling strategy and fetch the samples from dataset.
Custom multi-workers processing is used here to speed up data loading. However, the overall memory usage is the number of workers multiplied by the size of the parent process. Therefore, be careful of memory usage when loading a lot of data into the dataset.
If a built-in sampler has been set up and passed to Dataloader, Dataloader iterates sampler’s __iter__() method to fetch the samples.
Iterable-style Dataset Pipeline
Iterable-style Dataset Pipeline
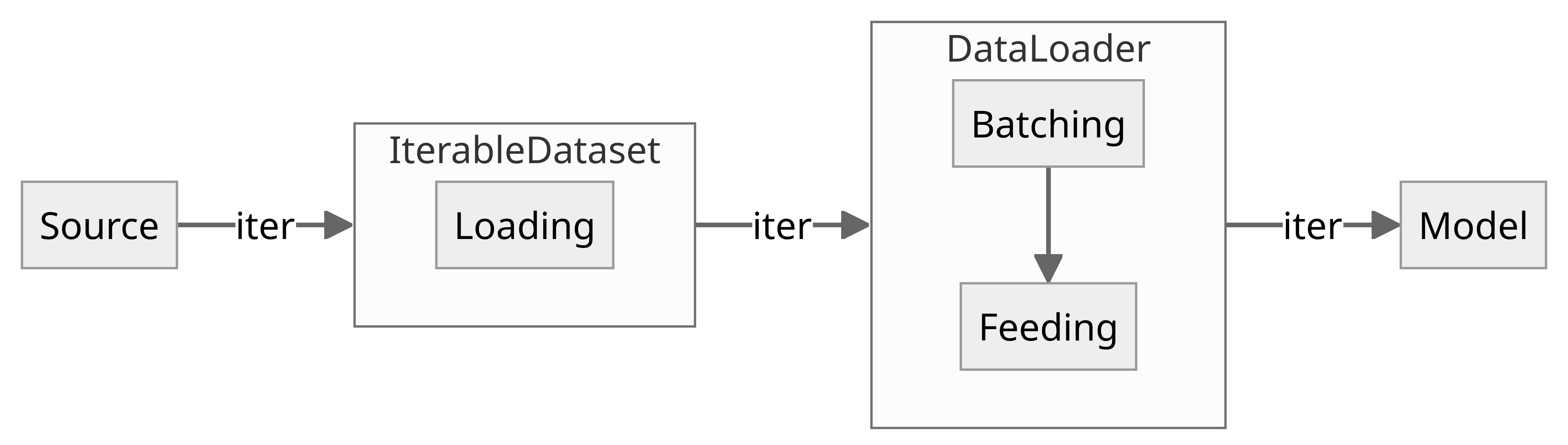
IterableDataset: Iterable-style Dataset Subclass
__init__(): Optional
__iter__(): Required
For data that cannot be loaded into memory all at once, such as streaming data, large data, or CPU-intensive data, use this method to manage the data loading process.
Custom multi-workers processing is used here to speed up data loading.
Build your own strategy to split the original data into parts, control the data loading speed, and adapt the batching to the feeding process speed.
Develop your own sampling strategy to load the different parts of the data from multiple workers.
DataLoader
__init__(): Constructor
Setup dataset, batching size , num_workers and more.
__iter__(): Iterator
Iterate over the IterableDataset to load the data in batches from all workers.
This is the feeding method for models.